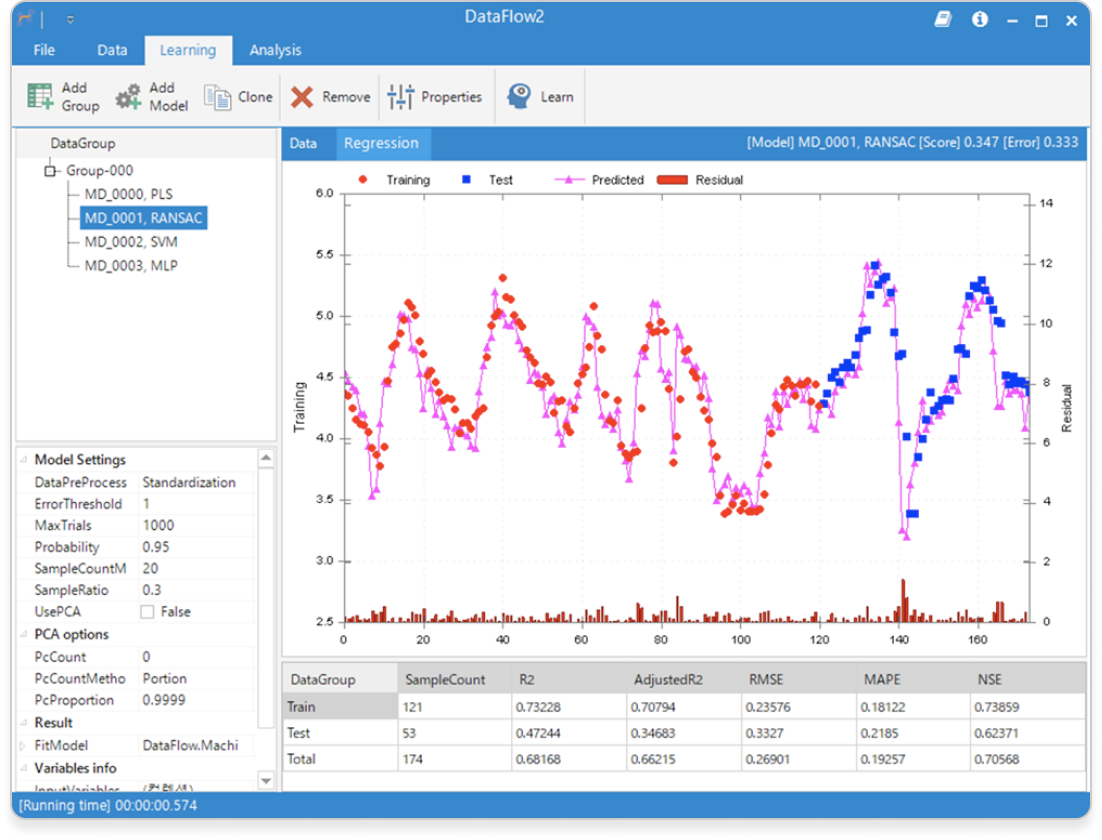
손쉬운 시작
DataFlow는 스프레드시트에서 데이터 조회 및 편집이 가능하며, 간단한 설정만으로 손쉽게 데이터를 분석할 수 있습니다.
- 엑셀(xls, xlsx) 또는 텍스트(csv) 파일 데이터 불러오기
- 학습 알고리즘 파라미터 기본값 제공을 통한 간편한 모델 학습 수행
- 학습된 모델 및 예측 결과 저장 / 불러오기
- 모델별 학습 설정 기본값 최적화
- 사용자 필요에 따라 알고리즘 파라미터 수정 가능
- 데이터 전처리 기능(입 · 출력 항목 중 데이터 변동이 없는 항목, 이상치 제거 등)
- 학습 및 테스트 데이터 선택 기능(순차, 무작위, 지정)
- 다수 모델 동시 학습, 학습 결과 요약 지원
- 한글 메뉴 및 사용자 지침서 지원
- 온라인 업데이트 지원
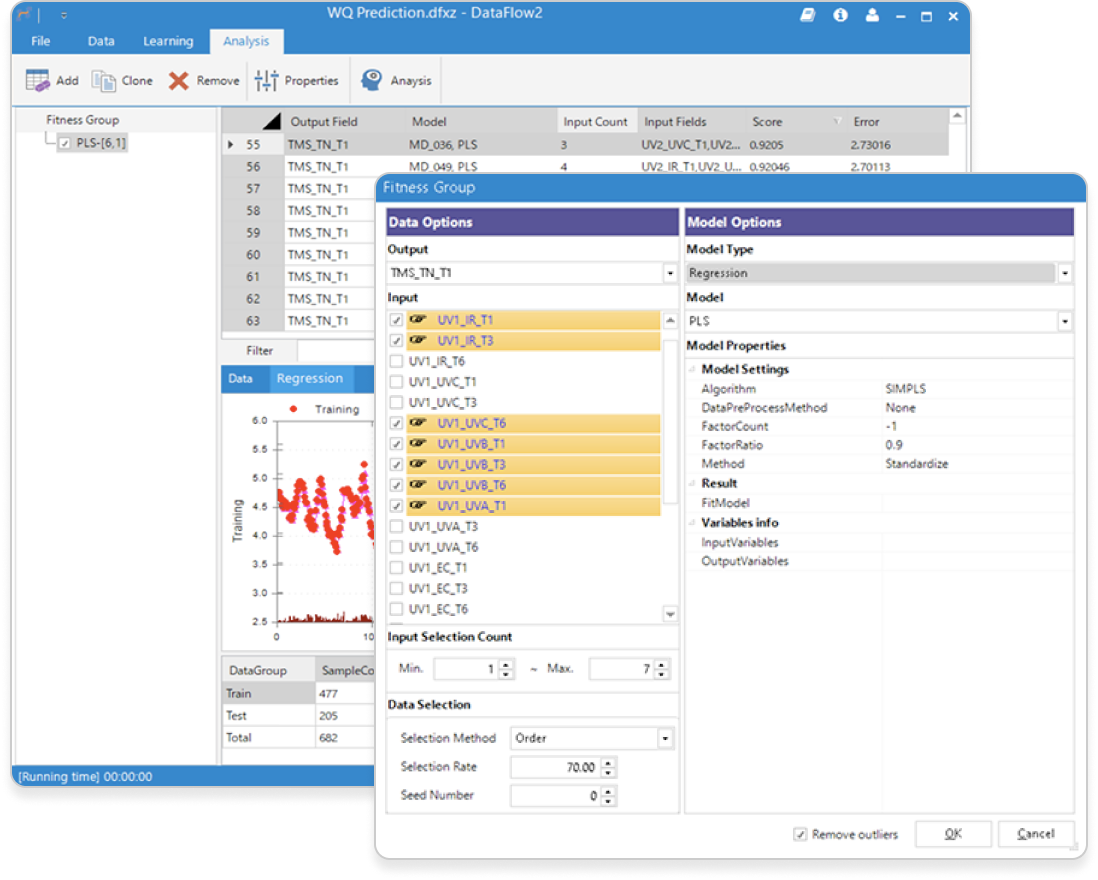
입력항목 선택 최적화
DataFlow는 학습 모델의 다양한 입력항목 조합에 따른
모델 학습결과를 비교하여 최적 모델을 선정합니다.
- 모델의 입력항목 개수 범위 지정
- 입력항목의 조합별 모델링 전체 수행
- 학습결과 성능이 우수한 순으로 결과 표시
- 성능이 우수한 모델이 많이 포함된 변수 추출
- 분석결과 복사 및 내보내기
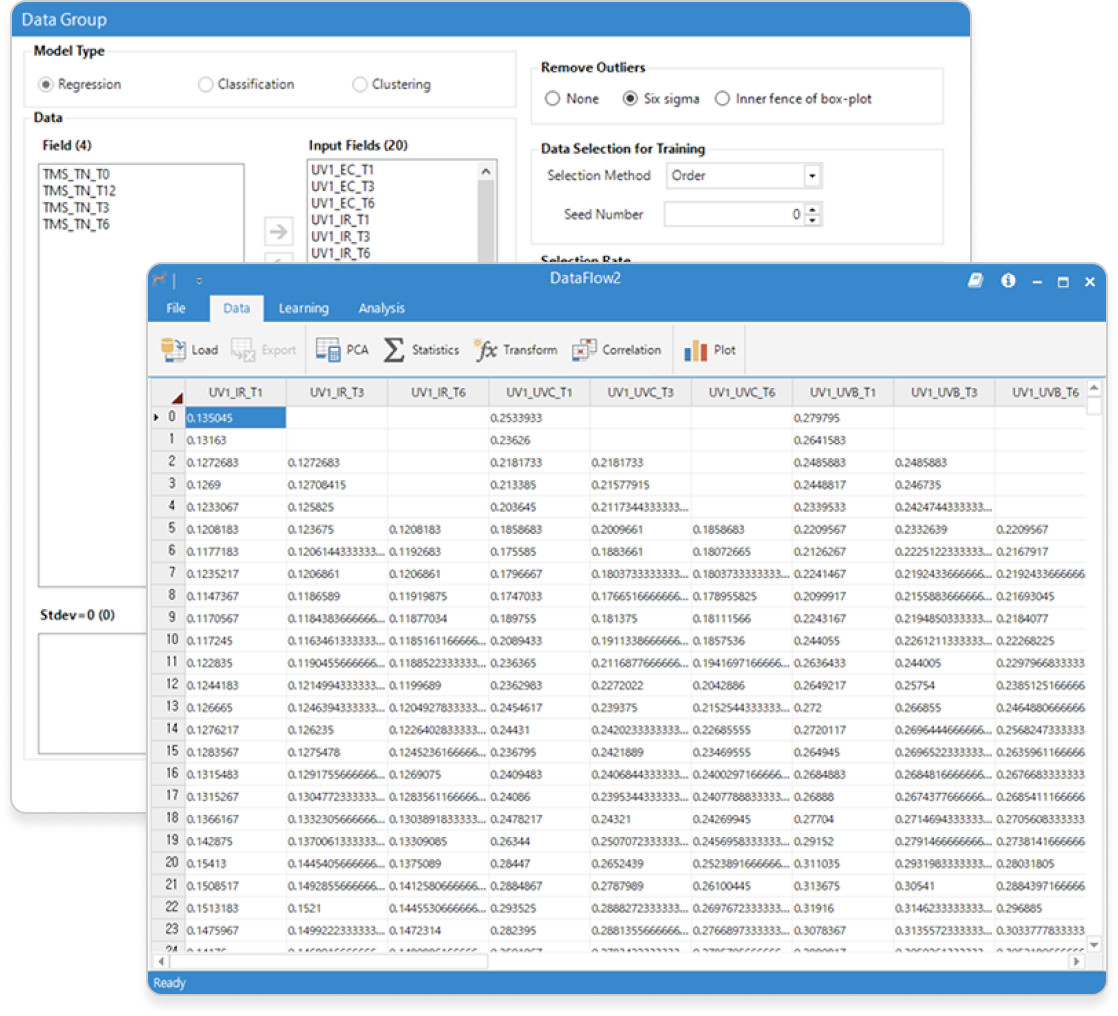
기초 통계 분석
DataFlow는 엑셀형태로 구성된 사용자데이터의 평균, 분산, 표준편차 등 단변량 통계량 연산과 주성분분석, 상관관계분석 등 다변량 데이터 분석기능을 제공하며, 예측/분류 모델의 입력항목을 선정하는데 도움이 되는 사전 분석을 수행할 수 있습니다.
- 기초통계량(평균, 분산, 표준편차, 최대값, 최소값, 중간값 등)
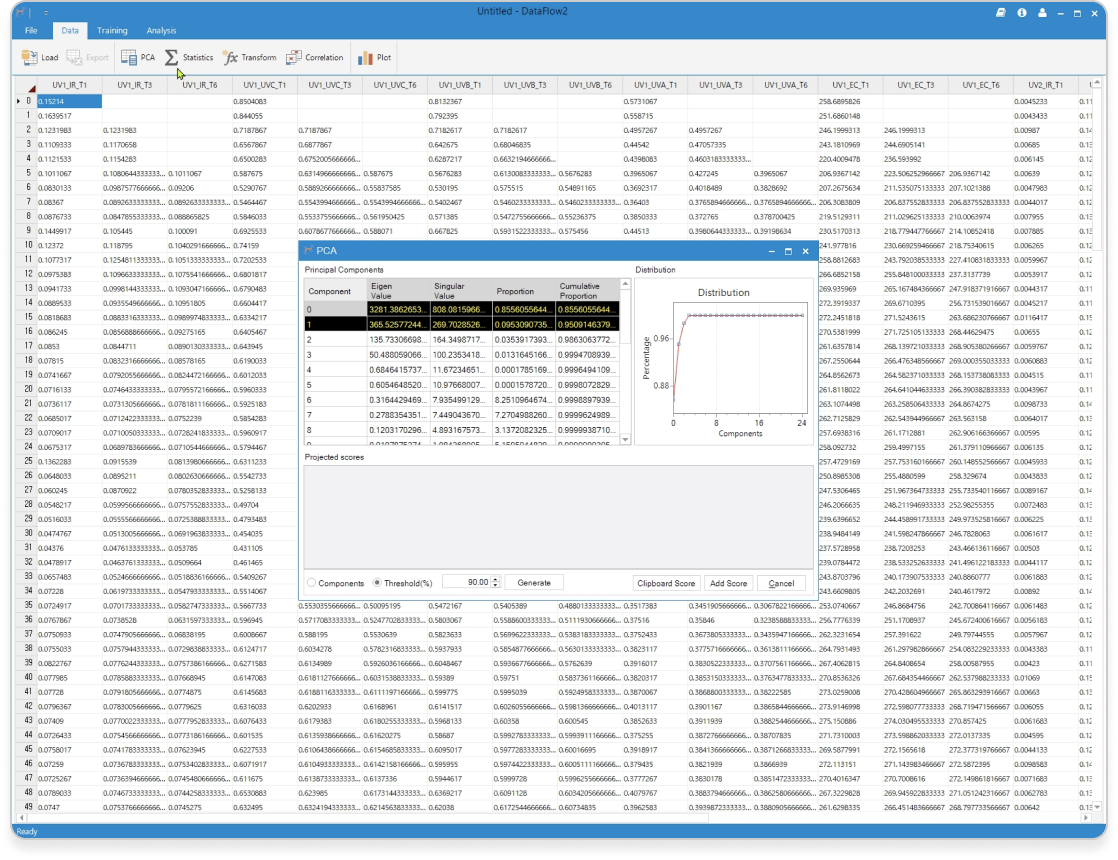
- 주성분 분석(PCA : Principal Component Analysis) 및 Score 변수 추가
- 상관관계 분석(CA : Correlation Analysis)
- 데이터 변환(Log, Power, Lead, Lag 등) 변수 추가
다양한 분석 기능 제공
모델링 목적에 맞게 사용할 수 있도록 다양한 알고리즘을 제공합니다. 각 알고리즘의 설정값은 다양한 사례로부터 도출된 최적값을 사용합니다.
- PLS(Partial Least Squares)
- SVM(Support Vector Machine)
- MLP(Multi-Layer Perceptron)
- MLR(Multivariate Linear Regression)
- RANSAC(Random Sample Consensus)
회귀분석
- PLS-DA(PLS – Discriminant Analysis)
- DT(Decision Tree)
- Neural Network
- KNN(K-Nearest Neighbor)
- Kernel-SVM
분류분석
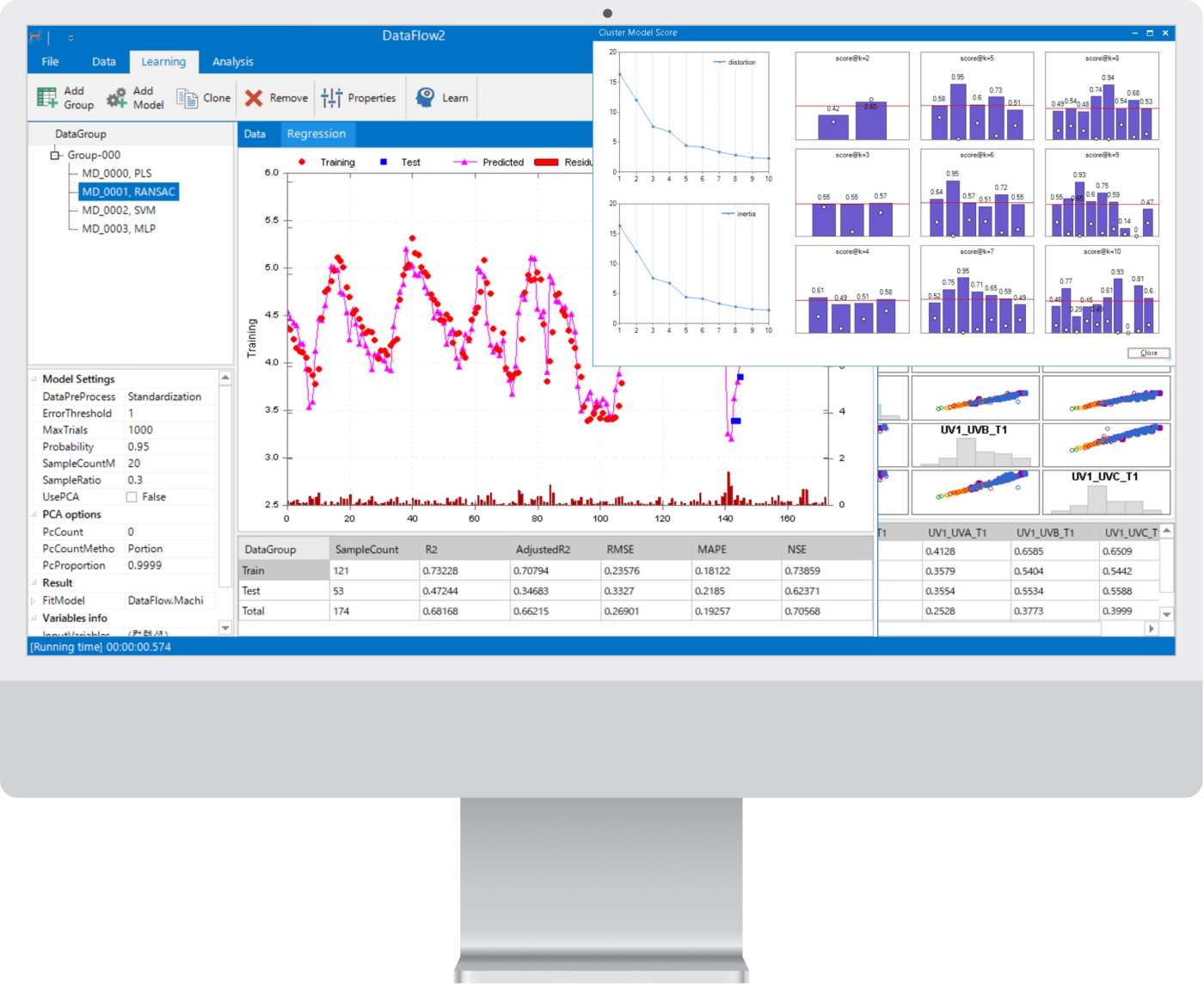
- K-Means
- Balanced K-Means
군집분석